前言
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 本身也是由诸多其他语言发展而来的,这包括 ABC、Modula-3、C、C++、Algol-68、SmallTalk、Unix shell 和其他的脚本语言等等。
像 Perl 语言一样,Python 源代码同样遵循 GPL(GNU General Public License)协议。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
而大多数人最开始接触Python都是通过网络爬虫。今天我就通过一个自己编写的网络爬虫例子来初步了解一下Python。
正文
什么是网络爬虫(Web Crawler)
简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前;
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
网络爬虫(Web Crawler)能做什么
- 做为通用搜索引擎网页收集器(google,baidu)
- 做垂直搜索引擎
- 科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
- 偷窥,hacking,发垃圾邮件…
我的理解:就是从网络中获取需要的大量数据,作为大数据等技术分析的原料。因为海量的数据本身是蕴含着很多规律,需要去发现和挖掘的。而这部分工作就需要之后的数据清洗、数据仓储、数据分析等技术手段。
为什么用Python写网络爬虫
所有语言都有相通的用处,比如写网络爬虫也有很多种语言选择。
工厂方法模式构成要素:
- C,C++:高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
- 脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
- C#(貌似信息管理的人比较喜欢的语言)
那最终为什么python能够胜任这个工作,为大多数人接受?
- 跨平台,对Linux和windows都有不错的支持。
- 科学计算,数值拟合:Numpy,Scipy
- 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2
- 复杂网络:Networkx
- 统计:与R语言接口:Rpy
- 交互式终端
- 网站的快速开发
爬虫的基本流程
用户获取网络数据的方式:
- 浏览器提交请求—>下载网页代码—>解析成页面
- 模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2。
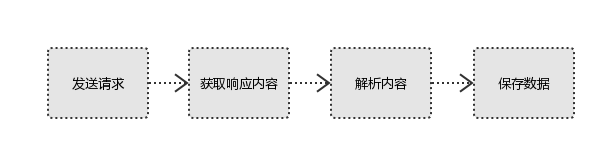
- 发起请求:
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码 - 获取响应内容:
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等 - 解析内容:
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等。 解析json数据:json模块
解析二进制数据:以wb的方式写入文件 - 保存数据:
数据库(MySQL,Mongdb、Redis)
文件
HTTP协议复习
编写网络爬虫需要对HTTP协议有一定了解。通过修改请求方式、请求URL、在响应体中过滤有用信息才能实现网络爬虫的功能。
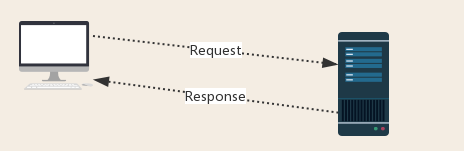
由图可知,用户通过发送请求给服务器,服务器根据请求发送响应。整个过程中有Request和Response两个消息。
- Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
- Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
Request详解:
- 请求方式:常见的请求方式:GET / POST
- 请求的URL:URL是全球统一资源定位符,用来定义互联网上一个唯一的资源 例如:一张图片、一个文件、一段视频都可以用url唯一确定
- 请求头:
- User-agent:请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户host
- cookies:cookie用来保存登录信息
- Referrer:访问源至哪里来(一些大型网站,会通过Referrer 做防盗链策略;所有爬虫也要注意模拟)
- 请求体:如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到;如果是post方式,请求体是format data
Response详解:
- 响应状态码:
- 200:代表成功
- 301:代表跳转
- 404:文件不存在
- 403:无权限访问
- 502:服务器错误
- 响应头:
- Set-Cookie:BDSVRTM=0; path=/:可能有多个,是来告诉浏览器,把cookie保存下来
- Content-Location:服务端响应头中包含Location返回浏览器之后,浏览器就会重新访问另一个页面
- preview:就是网页源代码,包括JSO数据、网页html、图片、二进制数据等。
Sina News Web Crawler
根据培训视频,一步一步完成了第一个网络爬虫–新浪新闻网络爬虫:
整个过程并不很顺利。遇到的困难主要有:
- 网站地址发生变更频繁,需要经常维护。这也是各大网站反爬虫的一种手段。因为编写的爬虫依赖的就是URL格式的统一,否则全自动就要变成“全得自己动”了。
- 很多网页上的信息是通过多个请求加载进来的,要知道一个网页的展示,可能需要发送了上百个请求,如何在这些Response中找到正确的信息也需要细心。比如此例子中的“评论数”。而且即使经过多次增加和修改,评论数量的收集也还是会有不完整。
此项目代码在Github
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
commentCountUrl = 'https://comment5.news.sina.com.cn/cmnt/count?format=json&newslist=gn:comos-{}:0'
commentCountUrl2 = 'https://comment.sina.com.cn/page/info?version=1&format=json&channel=cj&newsid=comos-{}'
import re
import requests
from bs4 import BeautifulSoup
import json
from datetime import datetime
def getCommentCount(newsurl):
m = re.search('doc-i(.+).shtml',newsurl) #根据新闻url找出新闻的id
newsid= m.group(1)
# print(newsid)
commentCountUrlFormat = commentCountUrl.format(newsid) #根据新闻id,组合出评论数量的链接
commentCountUrlFormat2 = commentCountUrl2.format(newsid)
#根据评论数量链接,取得评论数
res = requests.get(commentCountUrlFormat)
res2 = requests.get(commentCountUrlFormat2)
res.encoding='utf-8'
# print(res.text)
mm = re.search('\"total\":.*?(?=,)',res.text)
mm2 = re.search('\"total\":.*?(?=,)',res2.text) #这两个路径中只有一个是有返回值的,另一个没有返回值,需要判断
commentCount1=0
commentCount2=0
if mm is not None:
commentCountStr1 = mm.group(0).lstrip('"total":').strip()
commentCount1 = int(commentCountStr1)
if mm2 is not None:
commentCountStr2 = mm2.group(0).lstrip('"total":').strip()
commentCount2 = int(commentCountStr2)
#当第二个地址返回正确 ,但是第一个地址返回也不是空,知识内容是0,所以不为空的都要取,然后返回大的评论数
if commentCount1 > commentCount2:
return commentCount1
else:
return commentCount2
1
2
3
4
5
6
7
8
9
10
def getAuthor(soup):
show_author = soup.select('.show_author')
article_editor = soup.select('.article-editor')
if len(show_author)>0:
return show_author[0].text.lstrip('责任编辑:')
elif len(article_editor)>0:
return article_editor[0].text.lstrip('责任编辑:')
else:
return 'null'
1
2
3
4
5
6
7
8
9
10
11
12
def getNewsDetail(newsurl):
result = {}
res = requests.get(newsurl)
res.encoding='utf-8'
soup = BeautifulSoup(res.text,'html.parser')
result['title'] = soup.select('.main-title')[0].text
result['dt'] = datetime.strptime(soup.select('.date')[0].text,'%Y年%m月%d日 %H:%M')
result['newssource'] = soup.select('.source')[0].text
result['article'] = ' '.join([p.text.strip() for p in soup.select('.article p')[:-1]])
result['editor'] = getAuthor(soup)
result['commentsCount'] = getCommentCount(newsurl)
return result
1
2
3
4
5
6
7
8
def parseListLinks(pageUrl):
newsdetails = []
res = requests.get(pageUrl)
res.encoding='utf-8'
jd = json.loads(res.text)
for ent in jd['result']['data']:
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def getNewsTotal(start, end):
pageCommonUrl = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=10&page={}'
if str(start).isdigit() and str(end).isdigit():
if int(start)< int(end):
news_total = []
for i in range(int(start),int(end)):
newsurl = pageCommonUrl.format(i)
newsary = parseListLinks(newsurl)
news_total.extend(newsary)
return news_total
else:
return None
else:
return None
1
2
3
import pandas
df = pandas.DataFrame(getNewsTotal(11,13))
df.head(20)
执行效果如图:
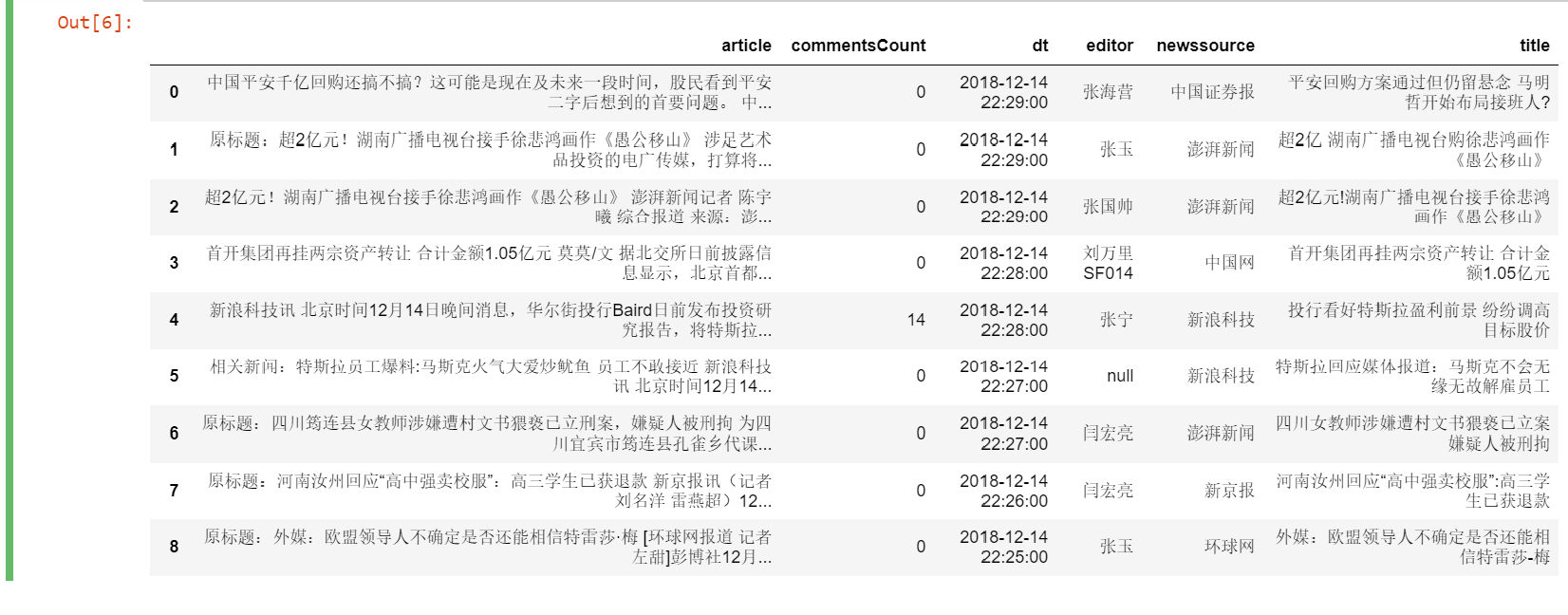
当然也可以通过命令将结果存储在数据库或者表格中。
1
df.to_excel('news_result.xlsx')
总结
有人对Python的理解还仅仅是脚本语言。其实Python是一个全能选手,尤其是在科研领域更是大放异彩。 在知乎上看到关于“你都用 Python 来做什么?”问题的回复,可以说是只有想不到没有做不到的。
参考资料
此次学习主要依赖于下面技术网站:
https://study.163.com/course/courseMain.htm?courseId=1003285002